DeepSeek & the Energy Question No One is Asking
- Adrien Book

- Jan 29, 2025
- 5 min read

Over the past few days, the AI industry has been in an uproar over a Chinese AI lab called DeepSeek. And for good reason. The company has just released a state-of-the-art Large Language Model “trained” for just $6 million, with just 2,000 Nvidia chips (the “R1”). That’s a fraction of the billions spent by hyperscalers like OpenAI, Google DeepMind, and Anthropic.
That low cost is coupled with the reveal that, since going live on January 20, DeepSeek-R1 has earned good marks for its performance… and rivals its larger competitors. There are also numbers flying around claiming it’s 27x times cheaper to operate than ChatGPT (per million token).
In short? We’re not just seeing yet another LLM launch. It’s a paradigm shift.
If DeepSeek can achieve GPT-4o-level performance at 1/100th of the cost, the implications extend far beyond model training. They force us to rethink everything about AI economics, infrastructure, and sustainability. That’s why the Nasdaq fell by 3% on Monday, driven by losses of chip maker Nvidia of nearly 17%.
But, amid all the debates over model quality, valuations, and the geopolitical AI race, some crucial questions are being ignored:
What does this mean for the hundred of data centers currently being built expecting very high compute density… that may now never come?
Why have we always measured data center efficiency in terms of power waste, but never questioned how efficiently IT actually uses that power?
What if the real AI bottleneck isn’t hardware availability — but the inefficiency of the software itself?
The Wrong War: Why Data Centers Focused on the .45, Not the 1
For years, the primary efficiency metric for data centers has been Power Usage Effectiveness (PUE). A PUE of 1.45 (the Middle East average) means that for every 1 kWh of IT power, an additional 0.45 kWh is consumed by air conditioning, lighting, toilets, etc.
The industry has poured billions into squeezing that .45 down, making buildings more efficient (“optimised rack positioning”, if you’re nasty), reducing overheads, and even investing in exotic liquid cooling systems to push PUE closer to 1.1, or even 1.05.
But myself — and many others — have long argued that this obsession with overheads misses the bigger picture. What if the real inefficiency isn’t in the cooling — but in the computing itself? What if, instead of cutting the .45, we started cutting the 1? Sure, that would lead to higher PUEs, that’s just math… but AI would be overall less energy hungry, at a time when its consumption is making headlines.
DeepSeek’s breakthrough proves this is not just theoretical:
Instead of brute-forcing AI development with ever-larger clusters of H100 GPUs, DeepSeek optimized every layer of the process
Using Mixture-of-Experts (MoE), load balancing innovations, and multi-head latent attention, they reduced compute overhead by orders of magnitude
They trained their latest model for under $6 million, using a relatively inefficient, U.S.-sanctioned H800 GPU cluster — and still achieved near GPT-4o levels of performance
In other words: DeepSeek squeezed the 1.
This raises a fundamental challenge for every AI lab, hyperscaler, and data center operator: if models can be made 100x more efficient, why are we still spending billions on dense, GPU-heavy clusters and extreme cooling solutions?
What Happens Next?
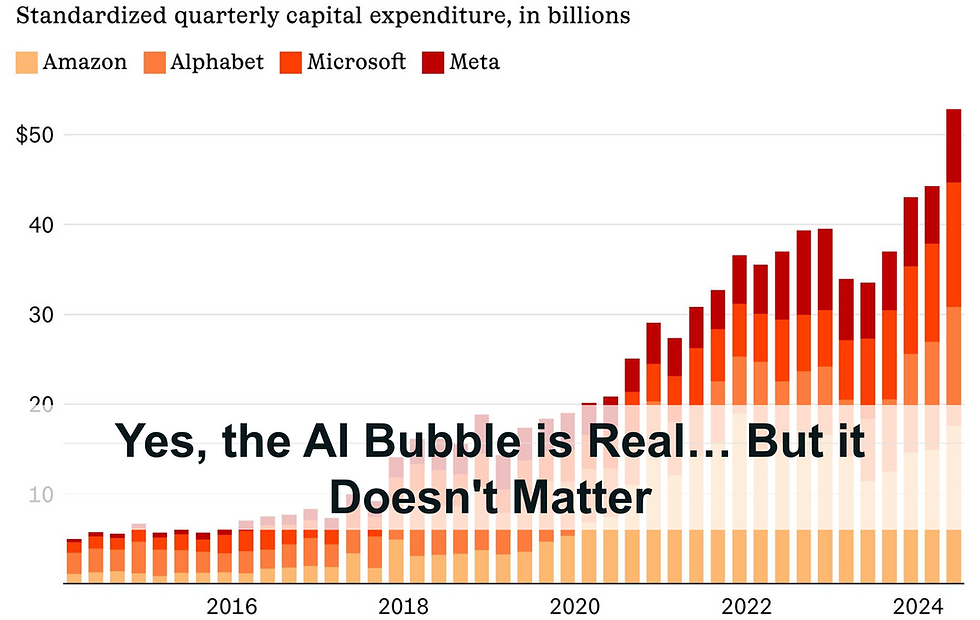
The AI industry runs on expensive, real-world infrastructure. Walls, electrical fit-out, cables, etc. Nvidia, OpenAI, Microsoft, Amazon, and Meta are spending hundreds of billions to scale up AI data centers — because their assumption has always been that better AI requires more compute.
DeepSeek R1 proves that assumption wrong, with massive consequences for the industry.
Nvidia’s Stranglehold Weakens
Nvidia has thrived because AI demand has outpaced supply. But if models become far more efficient, then:
Demand for expensive GPUs drops
Alternatives (AMD, Huawei Ascend, in-house AI chips) become viable
The Nvidia premium disappears
Today, Nvidia controls 80%+ of the AI chip market. But DeepSeek just demonstrated that model efficiency can offset hardware limitations, and that shifts the balance of power.
This shouldn't be over-stated; Nvidia is still the OG… but their foundation is more shaky today than it was yesterday.
The Data Center CAPEX Boom is Unsustainable
Tech giants are on track to spend over $2 trillion on AI infrastructure by 2030 ($250Bn in 2025). But DeepSeek’s success raises a hard truth: If AI efficiency keeps improving, most of that infrastructure may become obsolete before it’s even built.
Right now, data center expansions are based on 2023 assumptions about model scaling. But:
If training costs drop from $100M+ to single-digit millions, do we need such aggressive GPU cluster expansions?
If MoE and low-precision compute architectures become standard, does liquid cooling make sense?
DeepSeek may have just pulled the rug out from under the entire AI data center boom.
The AI Cost Structure Collapses
Right now, AI inference is expensive.
Every ChatGPT query costs 10x more energy than a Google Search.
Every LLM inference request burns through GPU memory and compute power.
But DeepSeek’s breakthroughs suggest that we could be approaching near-zero marginal costs for AI inference (going against the previous assumption that margins were going to become squeezed by Cost of Sales).
Open-source models trained using DeepSeek’s methods will flood the market
Enterprises will run AI models locally instead of paying OpenAI and Microsoft for API access
Cloud-based AI services will be forced to cut prices — drastically
This means AI could soon be embedded in nearly every consumer device at zero cost — and that has huge implications for AI business models.
The Final Question: What If AI No Longer Needs Hyperscalers?
DeepSeek just rewrote the AI economic playbook.
And that raises the biggest question of all:
What happens when AI no longer depends on Big Tech’s trillion-dollar infrastructure?
For years, we assumed that AI’s future belonged to hyperscalers — Microsoft, OpenAI, Google, and Nvidia — because only they could afford the astronomical compute costs.
But if DeepSeek’s innovations continue, AI could shift away from centralized cloud platforms entirely.
Imagine:
A future where every company runs its own AI locally — without needing OpenAI or AWS
A world where inference costs are close to zero, making AI-powered assistants, copilots, and tools essentially free
A collapse in demand for hyperscale data centers, because efficient AI doesn’t need them
As is often the case when such questions are asked, I am reminded of 2001. There were many, many losers out the dotcom bubble. But the winners are the giants that walk among us today… and are some of the most powerful economical entities the world has ever seen. I see no reason why this would not happen here again, as AI, just like the Internet, clearly has transformative potential.
In fact, it may be a net positive that companies are spending so much to build an AI infrastructure. The dotcom bubble was rough, sure, but the era’s over-build led to a glut in fibre that took almost a decade to backfill. Cheaply. The corpses of failed companies are the backbones of the digital world we know today.
For the last five years, AI progress has been measured by how many GPUs you could stack together. DeepSeek just proved that a radically different approach is possible.
The real AI revolution won’t be about bigger data centers — it will be about smarter AI. The hyperscaler business model is at risk. If models become cheap and open-source, centralized AI platforms will struggle to justify their costs. Instead of pouring billions into liquid cooling, we should be redesigning AI models to use less power in the first place.
I’ve long said that data center CAPEX is unsustainable past 2030. Maybe that number was 2025 (more or less — let’s not get carried away).
The future of AI belongs to efficiency — not brute-force scale.
Good luck out there.






















Heyy!!! I am Jack Smith. Looks like you’ve got a great collection! The designs are sleek and stylish. The Singapore Airlines Kathmandu Office assists travelers with flight reservations, ticket changes, cancellations, baggage inquiries, and special service requests. Passengers can obtain information about flights connecting Colombo with Singapore, offering seamless onward connections to destinations across Asia, Europe, Australia, and North America. The office also provides guidance on fare options, cabin classes, and KrisFlyer loyalty program benefits.
The Ryanair MAD Airport Terminal is located in Terminal 1 at Adolfo Suárez Madrid Barajas Airport. It provides travelers with an easy and low-cost route to popular European destinations. The terminal is designed for efficiency and includes check-in counters, self-service kiosks, dining options, and necessary passenger services. Whether you are traveling for business or leisure, this terminal offers a stress-free departure with clear signs and supportive staff. Travelers using Ryanair at MAD can enjoy comfort, convenience, and budget-friendly travel options all in one location.
Unlike traditional hackathons, an Ideathon emphasizes structured problem analysis and concept validation. Where U Elevate supports these initiatives by promoting idea-stage competitions that nurture early innovation.
CODESYS PLC enables development of IEC 61131-3 compliant control applications for industrial automation. It supports ladder logic, structured text, and function blocks, delivering scalable, real-time machine control solutions across manufacturing, process industries, and smart factory environments.
Really enjoyed this thoughtful piece on energy and motivation — it’s a great reminder to think deeply about what drives us every day! Speaking of meaningful choices, if you’re preparing for a celebration like a move or a new beginning, don’t forget to look for the best housewarming gifts that are both thoughtful and practical for someone starting a new chapter.